



















|
|
Leap-Second - 2012-June-30[This section is under development] I saw no showstopper bugs with either my FreeBSD or Windows systems, although many Linux bugs were reported.
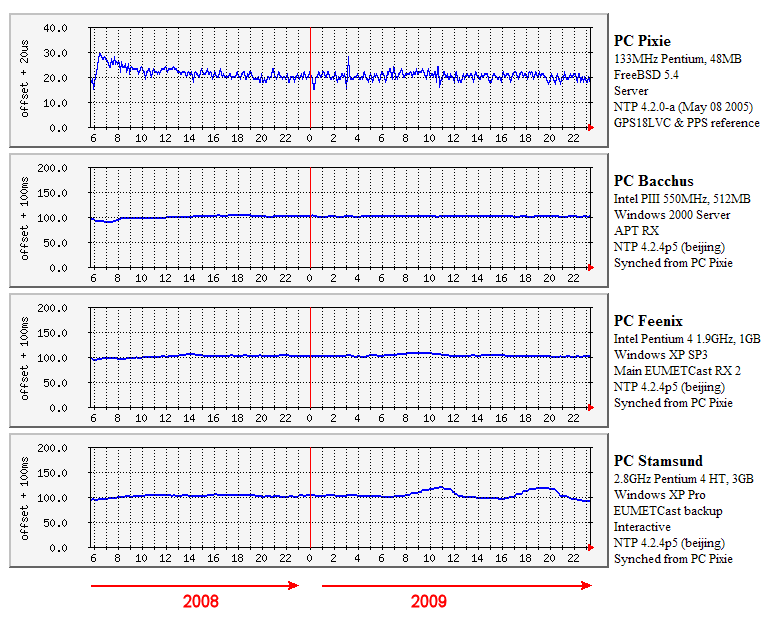
Offset graphs (148 KB PNG file) Zip archive of peerstats, loopstats and event log entries for GPS-synced PC Alta (338 KB Zip file) Event log entries for PC Alta Level Date and Time Source Event ID Task Category Warning 01/07/2012 01:24:33 NTP 2 None clock would have gone backward 1 times, max 1000612.1 usec Information 01/07/2012 01:24:32 NTP 3 None HZ 64.102 using 43 msec timer 23.256 Hz 64 deep Information 01/07/2012 01:00:00 NTP 3 None Leap second announcement disarmed Leap-Second - 2008-December-31By contrast with earlier events, the leap-second at the end of 2008 went of without a hitch. Here is a screen shot showing December 31 and January 01. As you can see, there was no disruption at the transition Dec 31 - Jan 01. The analog clock on my main PC took two seconds to go between 00:00:00 and 00:00:01, so my thanks to the person who wrote that part of the Windows NTP port for getting the code right! I left the heating on over the transition, as normally the temperature step at 06:00 in the morning and gradual cool-down late at night causes a change in the offset which is particularly noticeable in the GPS-synced PC Pixie, because of the accuracy it normally achieves. You can see the morning effect on the extreme left of the Pixie plot.
At 0630 UTC on January 31, just one of the servers I referenced indicated that it had not stepped, and was therefore a full second ahead, and NTP on the client had marked it a false-ticker - with an "X". Note from the graphs above that the presence of this one incorrect server did not affect PC Stamsund.
Bill Unruh posted output from his GPS18 LVC on the comp.protocols.time.ntp newsgroup. He writes:
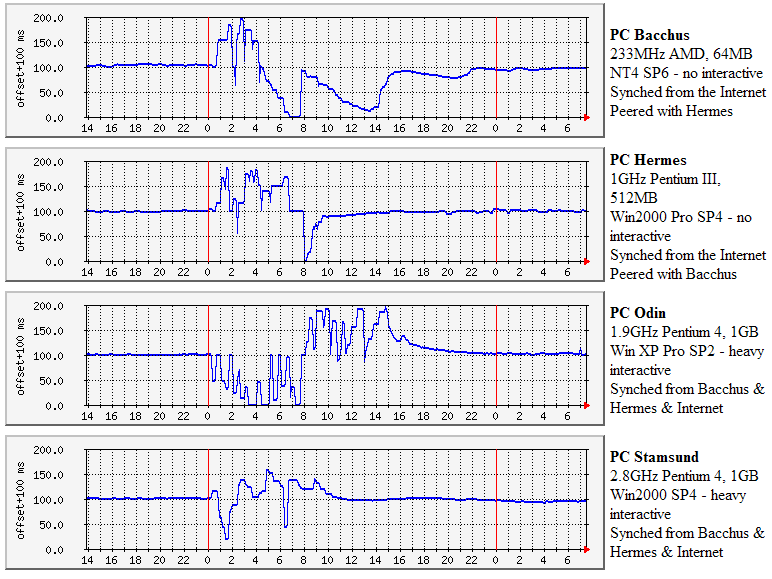
Other resourcesDavid Malone has a fascinating Web site at http://www.maths.tcd.ie/~dwmalone/time/leap2008.html where the behaviour of a number of systems (VLF and short-wave radio, NTP and DVB) are shown. This is a must-visit Web site if you are at all interested in leap-second issues. False Leap-Second - 2006-July-01On 2006 July 01 I noticed that the timekeeping on two of my PCs had gone wild. The offset graphs (shown below) were similar to ones I had seen before, with the value in the drift file being set to a large positive values (more than 400 ppm) and values which were grossly incorrect. Stopping NTP, restoring a correct drift value to the file ntp.drift, and restarting NTP cured the problem. I did this at about 07:30 clock. Noticing that the transient had started at 01:00 clock (00:00 UTC), I wondered if it had any connection with leap seconds. Sure enough, on looking in the Windows Event Log for the PCs in question, on both problem PCs, at 01:00 a positive leap second is inserted. Arrgh! The announcement wasn't coming from my own stratum 1 server (at least I hope it wasn't, as not all client PCs were affected). On PC Bacchus, a positive leap second was detected by NTP at 09:10 (clock) on June 06, the event log does not show which server provided this duff information. The NTP on that server was restarted on March 04 and was using NTP UK pool servers, plus ntp2c.mcc.ac.uk. On PC Stamsund, a positive leap second was detected by NTP at 09:17 (clock) on June 6. Its servers included UK pool servers, and 130.88.200.6 (utserv.mcc.ac.uk). (Interestingly, those are the two PCs which I didn't touch after the leap-second problems at the start of the year. Coincidence? On checking with the: ntpq -c rv <host-name> command neither the utserv.mcc.ac.uk server nor my own simple stratum-1 server was showing a leap-second flag (leap=00). (Thanks to David Malone for the syntax of this command - he checked a number of servers after the 2006 leap-second issue). Karel Sandler reported: "According to the www.pool.ntp.org there are 57 UK servers today. All these servers (3 S1, 32 S2, 20 S3 and 2 S4) have 'leap 00' (at Jul 1 23:36 UTC) and all those three S1 were OK according to the pool scores. But - one more server (S1) has been there until Jul 1 03 AM UTC. Maybe, don't know." So I am not 100% sure if the July transient was a hangover from the January problems, or if some servers were incorrectly sending out a positive-leap-second-is-due announcement. I will make the following suggestions: - to the NTP Pool managers: that the servers in the pool should be monitored for spurious leap-second announcements - to the NTP Developers: that NTP be more robust before acting on the leap-second announcement from a single server. My thanks to those who helped diagnose the problem. Screen-shot of the July 2006 transient on my PCs
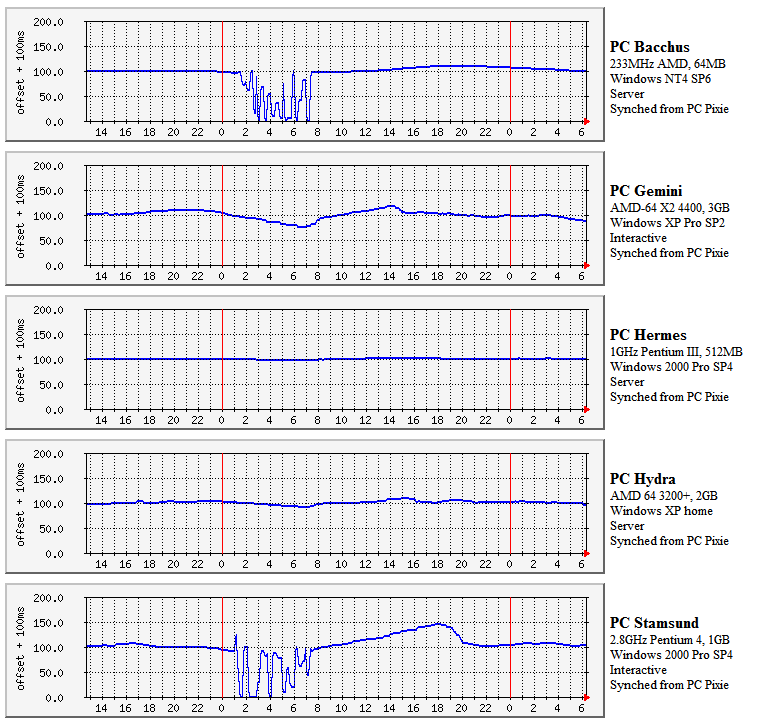
NTP Leap-Second Behaviour - 2005-2006The end of December 2005 was the first occasion for several years where a leap second was inserted in the UTC time scale to bring it back into line with the Earth's rotation. The software I use to keep my PCs' time correct, NTP, has full provision for handling the leap seconds, and can also control the computer either via the Unix kernel or by the Windows SetSystemTimeAdjustment routine, so that the leap second is handled smoothly. However, it seems that not all external systems were running the current software, or they they know about the leap second correctly. I was running two versions of the NTP software for Windows - both NTP 4.2.0b. On Bacchus and Hermes I had Meinberg version 1431, and on Odin and Stamsund Meinberg version 1436 - a beta test version which was able to correctly insert the leap-second on Windows, a function which the basic OS lacks. What happenedRather than being out on the streets of Edinburgh celebrating the New Year, I watched how the different systems handled the leap-second! It seemed that about half the Internet servers I sync to inserted the leap-second, but about half did not. This confused NTP, as it did not know which of the two clusters of servers were telling the correct time. Like many NTP users, I have no reference time source other than the Internet. This appeared to result in NTP assuming the worst - that the computers clock rate was way off, and it thought that the clock drift was nearly 500 parts per million, the maximum it could be. As a result, the timekeeping was all over the place (although mostly within the 128ms range NTP allows before it steps the computer clock). I left the computer in this state around 01:30 UTC. At 07:40 UTC I returned to see how things were going. Two of the PCs (Bacchus and Stamsund) whilst still having errors greatly in excess of their normal levels, at least had more reasonable (non-limiting) drift values, so I left them to try and sort themselves out. The other two PCs (Hermes and Odin) were still showing grossly incorrect drift values (as seen in the file ntp.drift), and were having gross time errors. Consequently, I decided to stop the NTP client, delete the drift file, and restart the client on those PCs. This resulted in Hermes setting down correctly with a couple of hours, but Odin took somewhat longer (10 hours) to determine a sensible drift value. ConclusionsIt's difficult to know what conclusions to draw, as I am not an NTP expert!
My thanks to Martin Burnicki of Meinberg, Germany, for providing the update to NTP for Windows which inserted the leap second. Martin also compared his code against a precision source, and the most interesting results appear here. Screen-shot of the January 2006 transient on my four PCs
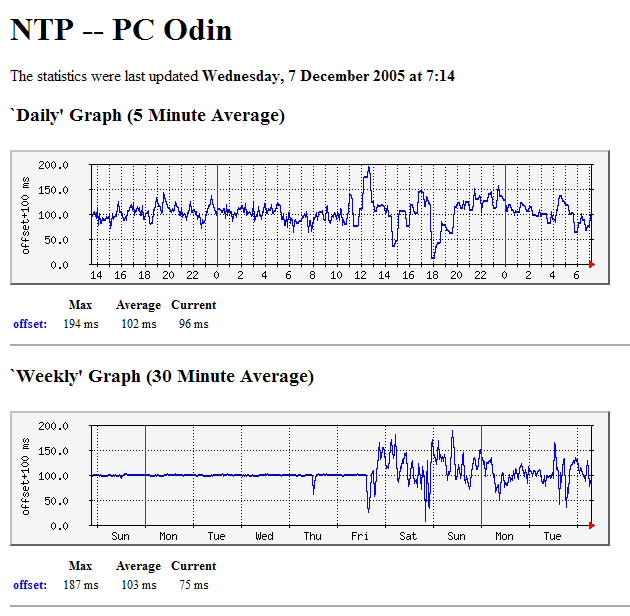
NTP Glitch - December 2005What happenedBriefly, something happened on 2005 December 02 (a software change probably), which caused NTP on my Windows XP Pro PC to show much more instability than I had seen since the installation of XP Service Pack 2. After much useful discussion on the comp.protocols.time.ntp newsgroup, I determined that running the MultiMedia timer continuously at 1ms resolution, cured the instability, which appears to be from the OS making time steps both when changing from regular to MM timer mode and when changing back again. I modified one of my own programs to provide a function to enable the MM Timer, and Martin Burnicki of Meinberg, Germany, provided a version of the Windows NTP software where that function could be enabled while the NTP software was running. I subsequently installed that version of the NTP software on Odin, where it completely cured the problem, and also on a Windows 2000 PC (Stamsund) which had always exhibited instability. It seems that running certain software (something like JavaScript or Flash under Internet Explorer) could set and reset the MM Timer mode, and thereby cause a timekeeping instability. The start of the problem - 2005, Friday 2nd December
Curing NTP instability on a Windows 2000 system
The instability of this system was completely cured by having the MM Timer running continuously, avoiding the glitches when it was enabled or disabled. The same software restored the Windows XP system to stable timekeeping. The glitch at the end of the graph is the leap-second issue described above. The Windows version of NTP has now been modified to include the -M parameter at startup which enables the MM timer, and thus provides much better timekeeping (on systems where this is a problem). Typical Drift ValuesThis is just for my own reference, but I might as well record it here as drift came into the leap-second discussion. The different values are recorded at different dates.
|
|
|